Go 源码分析:scheduler 工作流程
注:本文涉及的源码为 go 1.13 版本
最近一直在看 Go 调度器的源码,查了不少资料,对 goroutine 的调度过程有了一些了解,也对 Go 如何支撑高并发、并行计算有个大概的认识。
Go 调度器(scheduler)负责把各个 goroutine 分配到相应的操作系统线程 (OS thread )上执行,是 Go runtime 的两大组成部分之一,另一个是内存分配/垃圾回收(memory allocator/garbage collector)1 。
调度器相关的代码主要在 runtime 的 proc.go , runtime1.go , runtime2.go 等几个文件,此外还有一些 Go 汇编代码,这些代码大部分在 2015 年成形,至今没有大的修改,目前看来还是比较稳定的。
三个核心概念 GMP
在 Go 调度器的世界里,有三个主要的角色:M,P,G,调度过程基本围绕这三兄弟展开。
-
G,即是 goroutine,由 Go 代码产生, Go 程序在运行过程中通常会产生多个 goroutine。
-
M,是 Go 对操作系统线程(OS thread)的封装,可以看作操作系统线程,所有的 G 都交给 M 负责具体执行 。在调度过程中,M 有 spinning /non-spinning,parking/unparking 的状态,具体在下文介绍调度工作时解释。
-
P,是处理单元,全称 Processor。P 的数量表示最多可以有多少个线程在并行(parallel)执行,此外,P 也表示 G 被执行时必需的资源和上下文,每一个 M 必须绑定一个 P 才能执行 G。P 主要有 idle/running 等状态,同样在下文结合调度工作介绍
在运行过程中,这三个实体是紧密关联的。G 会出现在两个队列上,一个是 Global Run Queue(GRQ),另一个是 Local Run Queue (LRQ)。LRQ 有多个同时存在,每个 LRQ 都由一个 P 负责管理。而 GRQ 上的 G,通常是还没被分配到 LRQ 的。
每个M 工作时都关联着一个 P,按调度规则交替执行对应 LRQ 里面的 G。每个 LRQ ,可看作一个局部调度单位,调度队列上的 G。
他们的关系如下图:
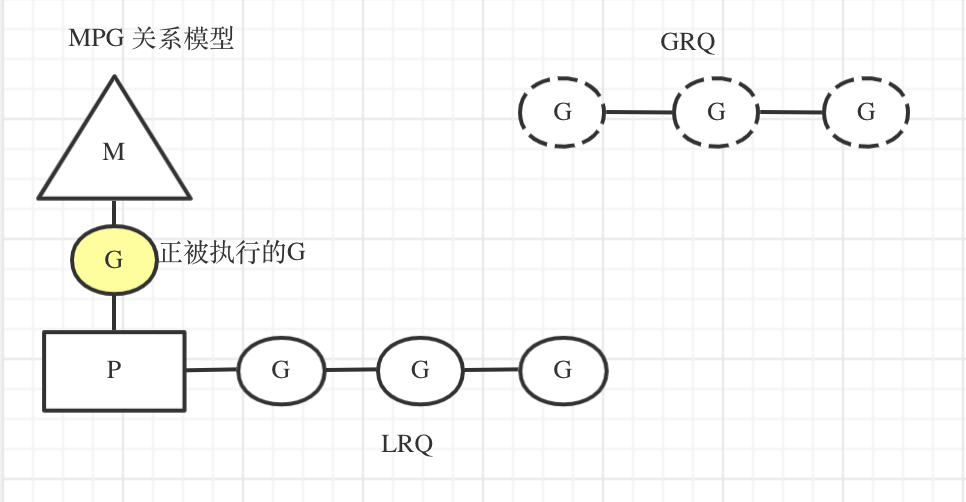
调度工作概况
工作窃取(work-stealing)
Go 调度工作有两个主要的场景,第一个是工作窃取(work-stealing)。假设现在分别有 M1P1, M2P2 各自在执行自己的 LRQ。M1P1 处理得比较快,先把自己的 LRQ 清空了,它会先去 GRQ 寻找可执行 G,如果 GRQ 也清空了,它就会去尝试去窃取其它 P 的 LRQ ,从那里取走一半的 G。
实现这一步骤的关键函数是 runtime/proc.go 的 func findrunnable() (gp *g, inheritTime bool)
|
|
系统阻塞(blocking)
另一个重要的调度场景发生在系统调用(syscall)等产生阻塞时。
例如 M1 在执行 G1 的过程中,G1 发出了一个 file I/O 的系统调用,将导致 M1 发生阻塞,等待必须系统调用完成。此时LRQ的无法被 M1 执行,如果只是干等,将是造成的资源浪费。此时,当前的 P 将被释放,自行去寻找其它 M 执行它的 LRQ。
这一过程主要调用了 runtime/proc.go 的以下几个函数:
- 调用
func entersyscallblock()/func entersyscallblock_handoff()准备释放 P - 调用
func handoffp(_p_ *p)释放 P - 调用
func startm(*p* *p, spinning bool),让 P 去寻找新的 M
当 G1 完成了系统调用,G1 将重新寻找一个 P,继续执行它。这一过程涉及到的主要函数如下:
- 调用
func exitsyscall()退出系统调用 - 调用
func exitsyscallfast(oldp *p)尝试找回原来的 P 或者一个空闲状态的 P - 如果第一次寻找 P 失败,再调用
func exitsyscall0(gp *g),再尝试找一个 P 或者放回 GRQ 等待
启动过程中的调度工作
Go 调度器的工作贯穿程序运行的整个过程,Go 程序一启动就开始相关工作。Go 启动流程如下图所示
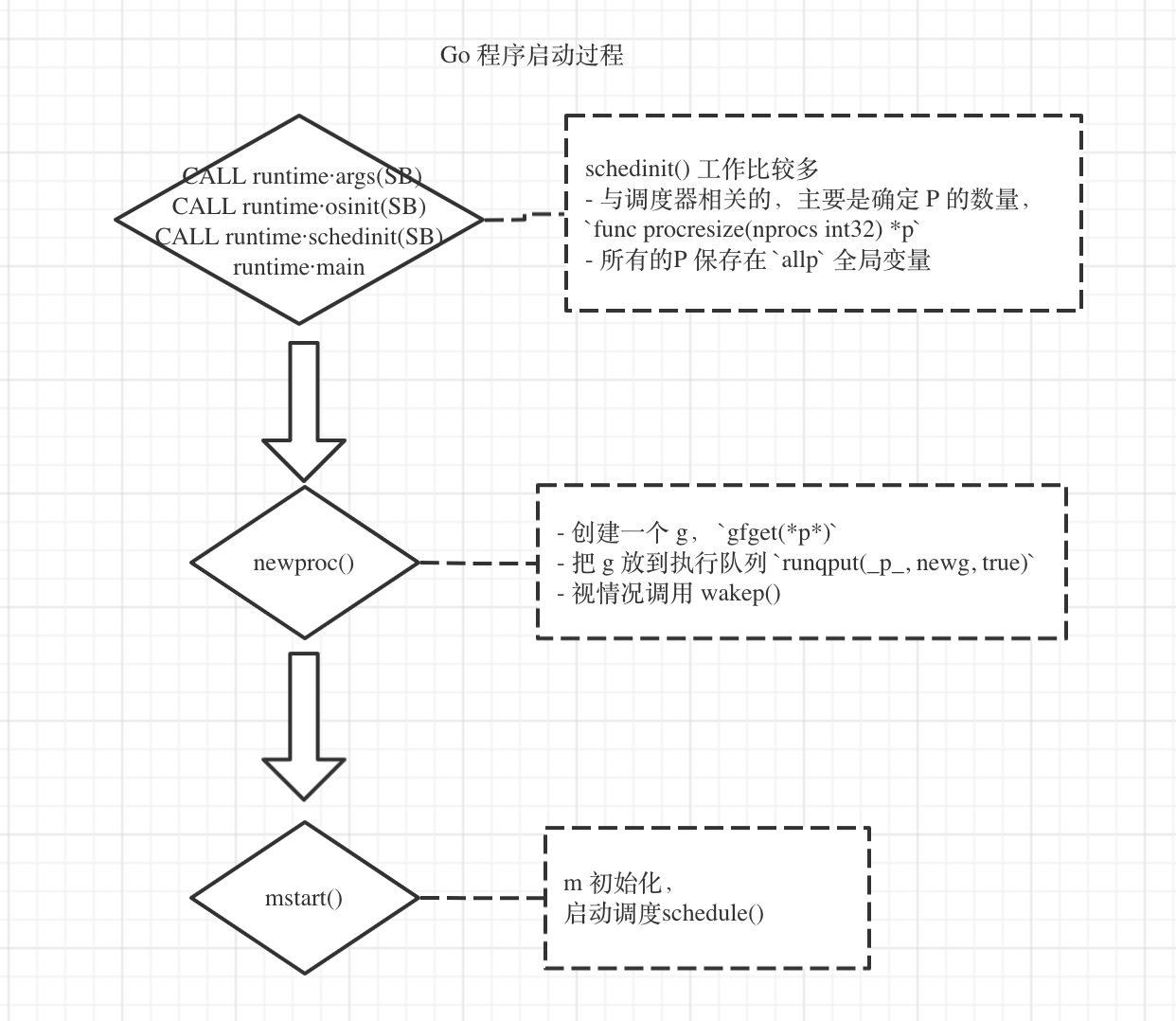
Go 程序的启动过程,网络上雨痕的《1.5.1 Golang 源码剖析》[github.com/qyuhen/book]有比较详细的介绍,这里侧重关注和调度器相关的部分。
启动的顺序几个比较重要的函数依次是:
- 调用
osinit(), 主要获取本机 CPU 的数量 - 调用
schedinit(),主要确定 P 的数量,P 默认和 CPU 的逻辑处理器数量(logical processors)相同,也可以通过环境变量GOMAXPROCS制定 - 创建 G,主要依靠
newproc()函数 func mstart(), 初始化 M,并调用schedule()函数开始调度
newproc() 函数的工作细节
newproc(),其任务是创建一个 G,并把它放入执行队列,主要通过 func newproc1(...) 实现,核心过程如下:
- 创建一个 g,
- 把 g 放到执行队列,通过
func runqput(_p_, newg, true)
|
|
这其中:
func gfget(*p*), 这是获取 G 最常用的方法,从空闲的 G 列表里获取,如果没有,再新创建一个。func runqput(*p* *p, gp *g, next bool),把 g 放到执行队列,优先放到本地执行队列 LRQ,如果 LRQ 已满,放到全局队列 GRQ,使用func runqputslow(_p_, gp, h, t)。
在完成 newproc() 函数之后,调用 mstart(),该函数完成 M 的初始化工作后,调用启动调度的函数 schedule(),程序至此开始进入“执行——调度——执行”的循环之中。
schedule() 调度工作流程
Go 调度的过程,其实就是 schedule() 函数运行的过程,它的工作流程大致如下图:
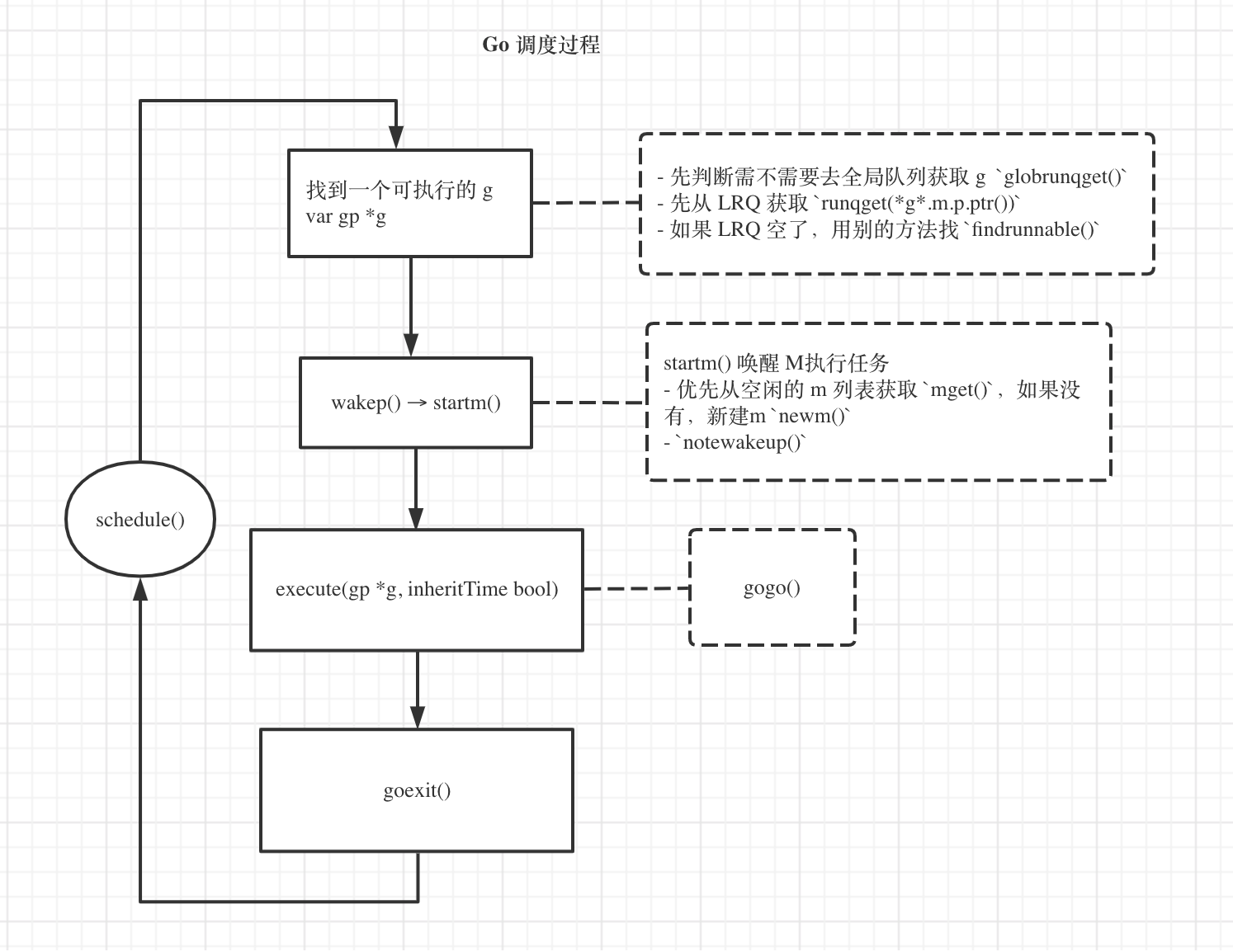
schedule()核心工作是,找到一个可执行的 G,安排它被执行。
|
|
细分下来,关键几步如下:
找到可执行的 G
这一步骤主要涉及的函数如下
func globrunqget(_p_ *p, max int32) *g,从 GRQ 获取一些 Gfunc runqget(*g*.m.p.ptr()),从当前的 LRQ 获取一个 G 来执行
wakep(),唤醒闲置的 P 去找事做
这一步触发是有条件的,atomic.Load(&sched.npidle) != 0 && atomic.Load(&sched.nmspinning) == 0,它的关键步骤是调用 startm(nil,true)
|
|
这里涉及到的func newm(fn func(), _p_ *p) 和 func notewakeup(n *note) ,都有调用操作系统线程相关的接口。
执行 G ,func execute(gp, inheritTime)
func execute(gp *g, inheritTime bool)的 关键步骤是 gogo(buf *gobuf),这个函数在 runtime/stub.go文件里是没有函数体的,看相关介绍是由编译器(compiler)生成的,不了解更多内容。
goexit() 并开启新一轮的 schedule()
执行gogo()之后,会执行 goexit(),这一步比较难发现,出现在更早前执行的 newproc1()函数,(更详细的介绍见 《1.5.1 Golang 源码剖析》P108):
|
|
而 goexit() 主要功能在 goexit1() (goexit0() )实现:
|
|
goexit0() 函数 核心内容如下:
|
|
调度工作大致就是这样就完成一个周期,并开始新的一轮调度。
最后,想到了一个问题,既然 P 的数量代表同时最多有多少任务并行执行,而且 P 的数量可以人为设置,那么是不是把 P 设置得越大性能就越好呢,是不是 P 等于 1 时就无法充分发挥 CPU 的计算能力?
其实并不是,这个问题 stackoverflow 有专门的讨论,go 核心开发者 Russ Cox 也写了专门的文章介绍 Go 1.5 GOMAXPROCS Default ,很值得一看。
参考资料
- Go scheduler 最通俗的介绍文章
- Scheduler Tracing In Go 命令行查看程序的调度细节
- Go Preemptive Scheduler Design Doc 调度器的设计文档
- Scalable Go Scheduler Design Doc 调度器的设计文档
- 深入golang runtime的调度
- 《Go scheduler 源码阅读》 很详尽
- Golang Internals, Part 6: Bootstrapping and Memory Allocator Initialization,了解 go 启动过程
- scheduling-in-go-part2,详尽,但有部分介绍不是很清晰